一,安装规划
1.1基本介绍
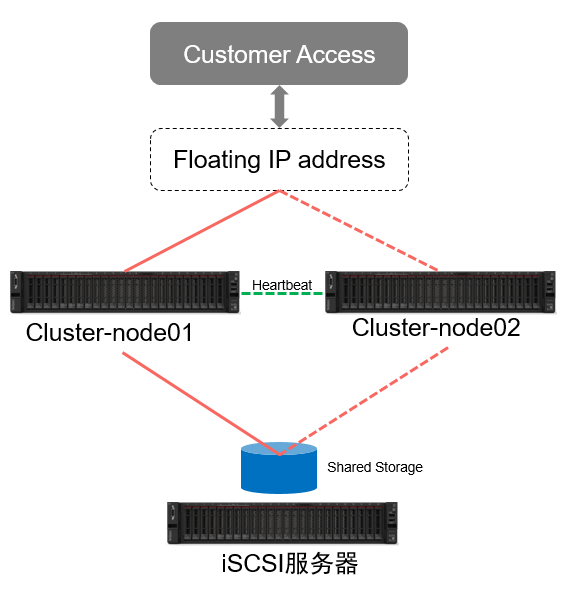
高可用性集群又称Failover-cluster(主动-被动集群)是生产环境中使用最广泛的集群类型之一。这种集群为您提供了服务的持续可用性,即使计算机组中的某个节点出现故障。如果服务器运行的应用程序由于某种原因(硬件故障)失败,集群软件(pacemaker)将在另一个节点上重新启动应用程序。
在生产环境中,您会发现这种类型的集群主要用于数据库、自定义应用程序和文件共享。故障转移不仅仅是启动一个应用程序;它有一系列的相关操作;像安装文件系统一样,配置网络和启动依赖应用程序。 CentOS 7 / RHEL 7使用pacemaker支持故障转移集群,我们将在这里讨论如何将apache (web)服务器配置为高可用的应用程序。正如我所说,故障转移是一系列操作,因此我们需要将文件系统和网络配置为资源。对于文件系统,我们将使用iSCSI存储中的共享存储。
1.2节点规划
节点
Hostname
IP地址
Node1
node01.cluster.local
172.16.10.11
Node2
node02.cluster.local
172.16.10.12
iSCSI-Server
iscsinode.cluster.local
172.16.10.13
1.3 安装环境

本次安装采用VMware虚拟机的形式部署三个节点,所有节点OS版本为CentOS 7.5
二,部署iSCSI节点
2.1 说明
共享存储是高可用性集群中的重要资源之一,它包含运行中的应用程序的数据。集群中的所有节点都可以访问共享存储中的应用和数据,SAN是生产环境中使用最广泛的共享存储;在这里,我们将使用iSCSI存储配置一个集群用于演示目的。
2.2 开始部署
在这里,我们将在iSCSI服务器上创建50GB的LVM磁盘,作为集群节点的共享存储。
2.2.1 查看可用磁盘
fdisk –l grep –i sd

我们将使用/dev/sdb来创建LVM
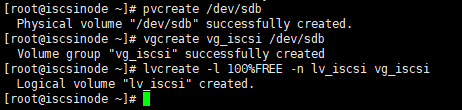
2.2.2 创建LVM
执行以下命令:
pvcreate /dev/sdb
vgcreate vg_iscsi /dev/sdb
lvcreate –l 100%FREE –n lv_iscsi vg_iscsi
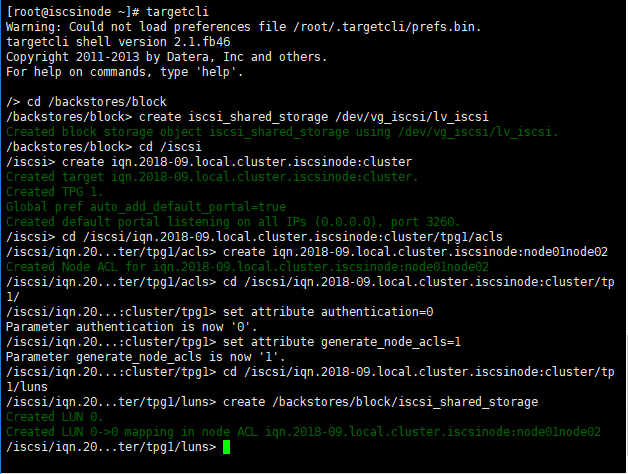
2.2.3 创建iSCSI Target
安装targetcli package, yum install targetcli -y


配置iSCSI Target,执行以下命令:
targetcli
cd /backstores/block
create iscsi_shared_storage /dev/vg_iscsi/lv_iscsi
cd /iscsi
create iqn.2018-09.local.cluster.iscsinode:cluster
cd /iscsi/iqn.2018-09.local.cluster.iscsinode:cluster/tpg1/acls
create iqn.2018-09.local.cluster.iscsinode:node01node02
cd /iscsi/ iqn.2018-09.local.cluster.iscsinode:cluster/tp1/
set attribute authentication=0
set attribute generate_node_acls=1
cd /iscsi/iqn.2018-09.local.cluster.iscsinode:cluster/tp1/luns
create /backstores/block/iscsi_shared_storage
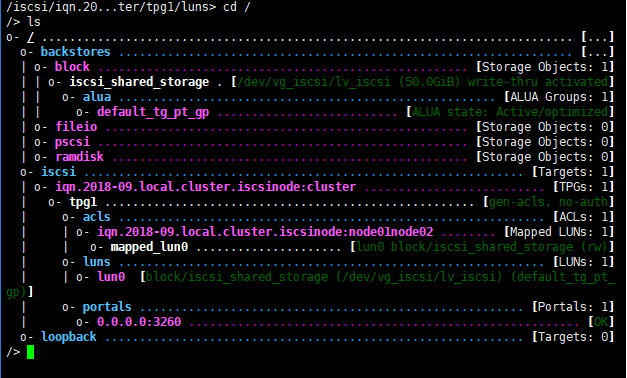
检查配置并保存退出
cd /
ls
saveconfig
exit
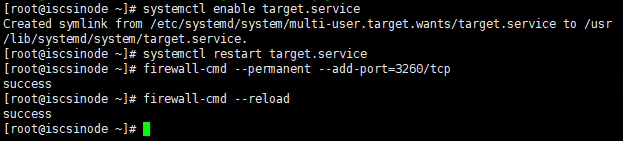
Enable并重启target服务

添加防火墙规则
三,配置iSCSI Initiator
分别在两台HA节点上执行以下操作配置iSCSI Initiator
3.1 安装iSCSI Initiator
yum install iscsi-initiator-utils -y

3.2发现Target
iscsiadm -m discovery -t st -p 172.16.10.13

3.3 修改iscsi initiator名称
vi /etc/iscsi/initiatorname.iscsi

3.4 注册target
Iscsiadm –m node –T iqn.2018-09.local.cluster.iscsinode:cluster –p 172.16.10.13 -l

3.5 重启并Enable Initiator服务
systemctl restart iscsid.service
systemctl enable iscsid.service

四,配置HA集群节点
4.1 配置LVM
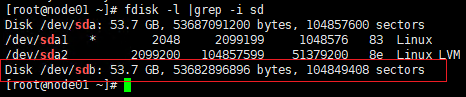
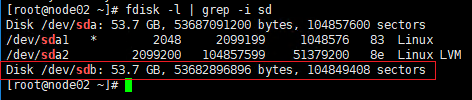
执行以下操作,在两个节点上创建LVM
确认两个节点都已经可以看到iSCSI共享存储
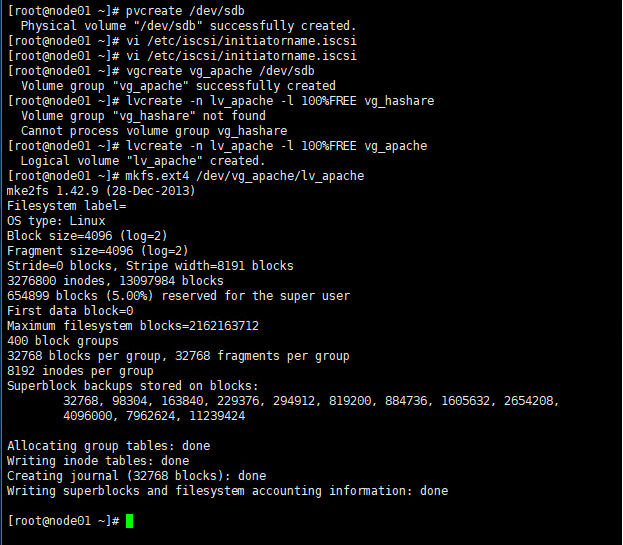
4.2 在节点1上创建LVM
执行以下操作:
pvcreate /dev/sdb
vgcreate vg_apache /dev/sdb
lvcreate -n lv_apache -l 100%FREE vg_apache
mkfs.ext4 /dev/vg_apache/lv_apache
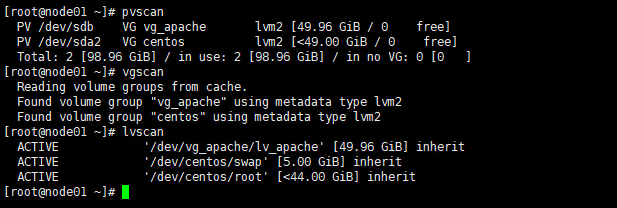
4.3 在节点2上验证LVM
pvscan
vgscan
lvscan
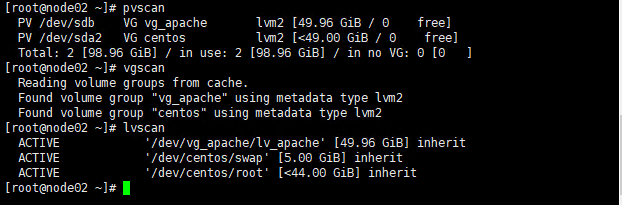
4.4 确认LVM配置正确
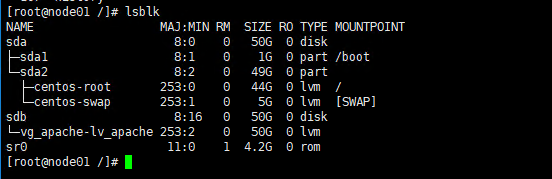
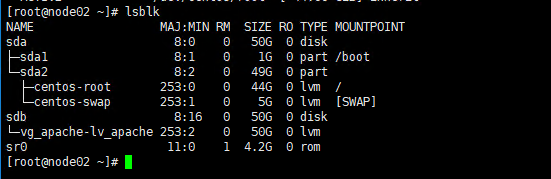
4.5 编辑Hosts
在每个节点上为所有节点创建一个主机条目,集群将使用主机名相互通信。在所有集群节点上执行任务。
vi /etc/hosts

4.6 安装集群软件pacemaker
在两个节点上安装pacemaker,yum install pcs fence-agents-all -y

4.7 添加防火墙规则
firewall-cmd –permanent –add-service=high-availability
firewall-cmd –add-service=high-availability
firewall-cmd –reload
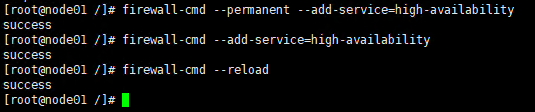
Firewall-cmd –list-service

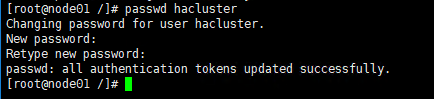
4.8 集群管理账号设置
为hacluster用户设置密码,此为群集管理帐户。建议为所有节点设置相同的密码。
4.9 启动集群服务
执行以下命令启动集群服务并设置为开机自动启动
systemctl start pcsd.service
systemctl enable pcsd.service

五,创建集群
5.1 节点授权
使用以下命令授权节点,在任何一个节点中运行该命令即可
pcs cluster auth node01.cluster.local node02.cluster.local

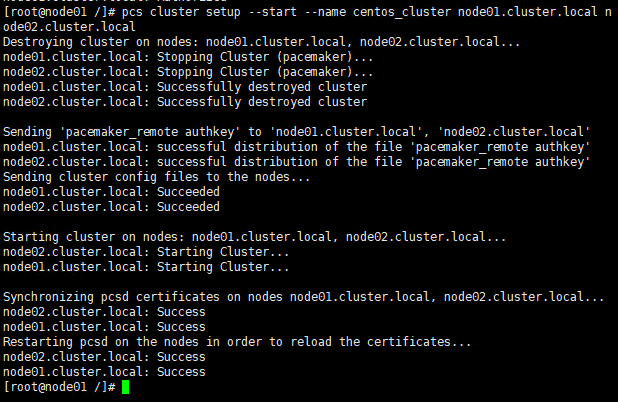
5.2 创建集群
pcs cluster setup –start –name centos_cluster node01.cluster.local node02.cluster.local
设置开机自动启用集群,否则每次重新启动系统时都需要手动启动集群。
pcs cluster enable –all

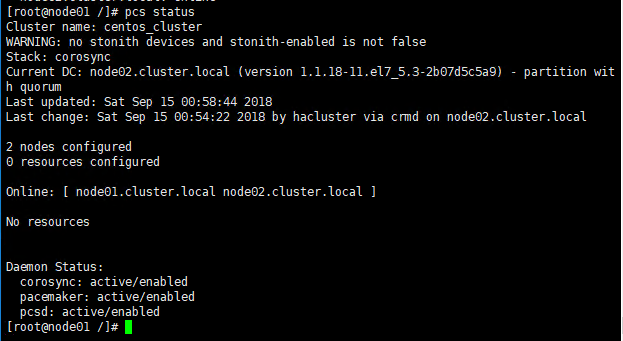
5.3 查看集群状态
pcs cluster status
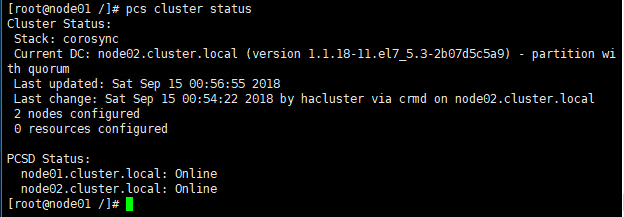
运行下面的命令以获得关于集群的详细信息,包括其资源、pacemaker状态和节点详细信息
pcs status
六,配置Apache
经过上面的配置,HA高可用集群已经创建完成,下面我们通过配置简单的Apache服务来验证集群的高可用。
6.1 安装Apache
在两个节点上安装Apache
yum install –y httpd
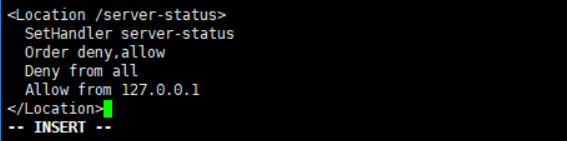
编辑Apache配置文件,在配置文件中添加下图中的内容,两个节点上都要编辑
vi /etc/httpd/conf/httpd.conf
6.2 配置Apache使用共享存储
配置使用共享存储来存储web内容(HTML)文件。在Node01上执行以下操作
mount /dev/vg_apache/lv_apache /var/www/
mkdir /var/www/html
mkdir /var/www/cgi-bin
mkdir /var/www/error
restorecon –R /var/www

编辑index.html,这里使用输入重定向的方式简单编辑了一下, 也可以通过VIM直接编辑
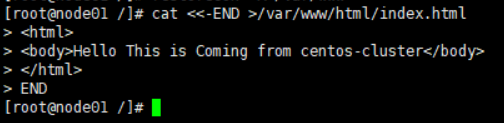
编辑完成后,umount /var/www 注意如果不执行此操作,集群中的其它节点将无法正常访问apache目录
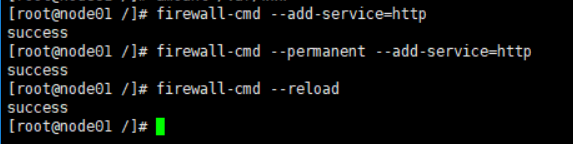
添加防火墙规则
firewall-cmd –add-service=http
firewall-cmd –permanent –add-service=http
firewall-cmd –reload
6.3 创建共享资源
为Apache服务器创建一个文件系统资源,并使用iSCSI服务器的共享存储。
pcs resource create httpd_fs Filesystem device=”/dev/mapper/vg_apache-lv_apache” directory=”/var/www” fstype=”ext4” –group apache

6.4 配置Floating IP
创建一个IP地址资源,该 IP为访问Apache的虚拟IP。用户将使用此ip地址访问Apache web内容,而不是访问单个节点的IP地址。 将地址设置为172.16.10.10
pcs resource create httpd_vip IPaddr2 ip=172.16.10.10 cidr_netmask=24 –group apache

6.5 配置heartbeat
创建一个Apache资源,它将监视Apache服务器的状态,并在出现任何故障时将资源移动到另一个节点
pcs resource create httpd_ser apache configfile=”/etc/httpd/conf/httpd.conf” statusurl=”http://127.0.0.1/server-status“ –group apache

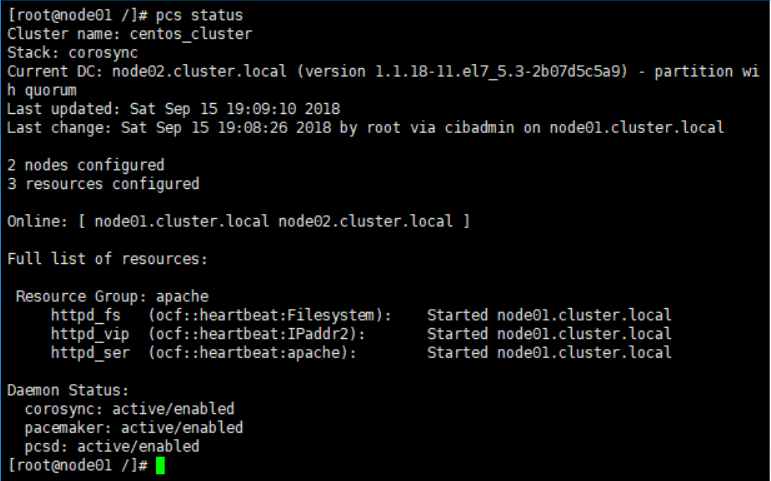
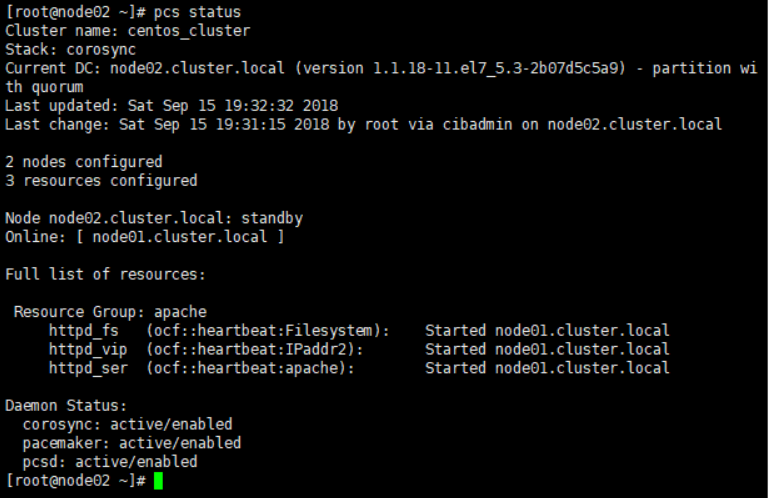
6.6 检查集群状态
在两个节点上检查集群状态,如下图,可以看到节群中两个节点都是在线状态,并且Apache运行在node01上。
七,验证集群
7.1访问Apache
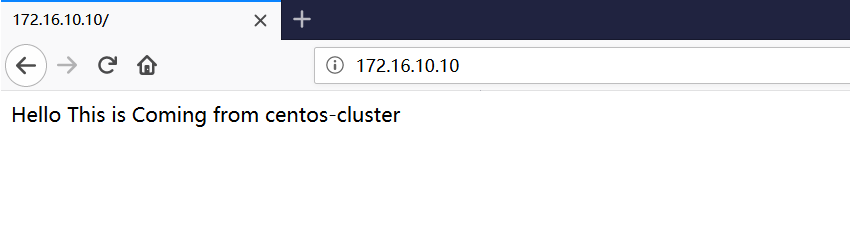
确认集群启动并运行后,通过浏览器访问Apache的虚拟ip,确认可以正常访问
7.2 停止node01的集群服务
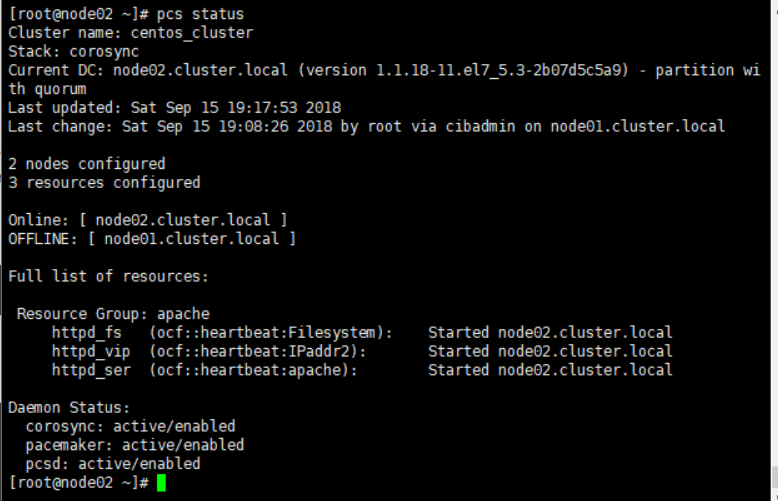
因为当前Apache服务是运行在node01上,所以我们现在关闭node01的集群服务,来模拟节点1出现故障不可访问
pcs cluster stop node01.cluster.local

在节点2上查看集群状态,可以看到现在只有node02是在线状态,并且Apache服务已经切换到node02上
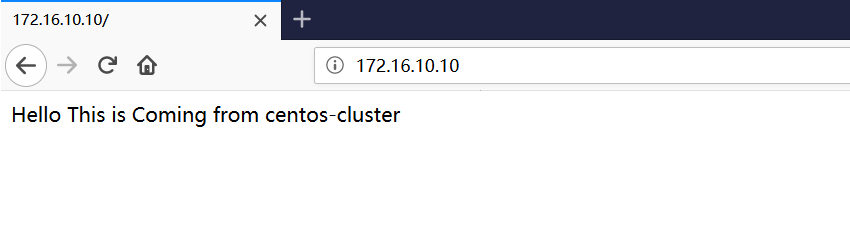
关闭浏览器,并重新打开访问Apache虚拟IP地址,确认Apache依然可以正常访问。 这说明HA高可用是有效的,web服务已经从node01切换到node02上。
7.3 资源回切
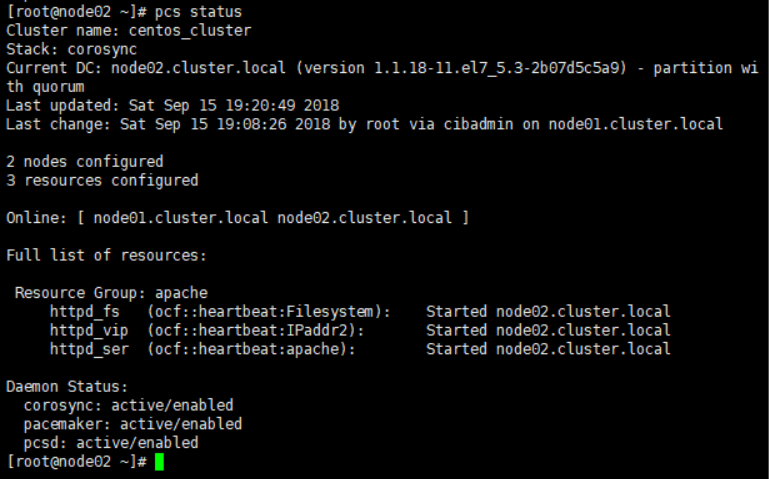
当故障节点修复后,如果我们需要将服务重新切换到修复的节点上运行,可按以下方 式操作
重新启动Node01的集群服务

可以看到两个节点都已经处于在线状态,但是Apache服务还是运行在node02上,并没有自动切换回node01
在node02上运行使用以下命令,将node02节点设置为备用,Apache服务将会切换回node01
pcs node standby
八,关于隔离设备(Fencing Devices)
隔离设备是一种硬件/软件设备,它通过重置节点/断开问题节点访问共享存储的连接。由于我这里的实验是以VM的方式搭建的集群环境,所以没有配置隔离设备。对于实际的生产环境,或者以物理机部署的高可用集群来说,隔离设备(Fencing Devices)是集群的重要组成部分。使用隔离设备可以防止“脑裂”现象的产生,从而保证集群的正常运行。
关于“脑裂”:
当集群中的两个节点(或者多个节点)同时认为自已是唯一处于活动状态的服务器时,就会出现争用资源的情况,这种争用资源的场景即是所谓的“脑裂”(split-brain)或”区间集群“(partitioned cluster)。
导致“脑裂”的原因通常有以下几点:
● 心跳链路故障:比如当联系2个节点的“心跳线”断开时,由于相互失去了联系,都以为是对方出了故障,这时两个节点都开始控制服务和资源,出现资源争抢,导致业务服务不可用
● 活动节点假死:当活动节点负载过高,系统响应变慢,这时有可能对心跳的回应也出现停止或延迟,备用节点再接收不到主节点的回应后,判断主节点已经出现故障,开始接管资源和服务,出现资源争抢,导致业务服务不可用
● 磁盘故障:如果心跳方式采用的是共享磁盘的方式,当共享磁盘出现故障时,节点之间失去联系,同样会导致各节点之间开始资源争抢,导致业务服务不可用。产生脑裂现象
关于隔离设备(Fencing Devices)的详细配置,可通过以下链接进行了解:
https://access.redhat.com/documentation/en-us/red_hat_enterprise_linux/7/html/high_availability_add-on_administration/s1-fenceconfig-haaa



