简介
在介绍Nutanix数据保护功能之前,首先简单了解一下数据保护领域的三大指标:DR、RTO和RPO。
● Disaster Recovery (DR)
灾难恢复(Disaster Recovery, DR)是安全规划的一个领域,旨在保护组织免受重大负面事件的影响。
DR允许组织在灾难发生后维护或快速恢复关键任务功能。容灾系统是指在相隔较远的异地,建立两套
或多套功能相同的IT系统,互相之间可以进行健康状态监视和功能切换,当一处系统因意外(如火灾
、地震等)停止工作时,整个应用系统可以切换到另一处,使得该系统功能可以继续正常工作。容灾
技术是系统的高可用性技术的一个组成部分,容灾系统更加强调处理外界环境对系统的影响,特别是
灾难性事件对整个IT节点的影响,提供节点级别的系统恢复功能。从其对系统的保护程度来分,可以
将容灾系统分为:“数据容灾”、“应用容灾”和“业务级容灾”。
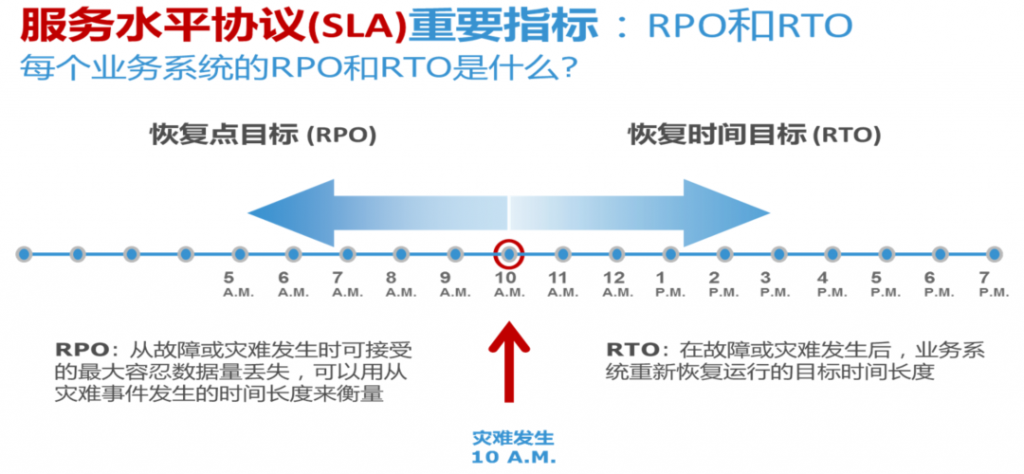
● Recovery Point Objective (RPO)
RPO是中断后允许的时间间隔,允许在不超过最大允许阈值的情况下丢失大量数据。RPO指定在网络停
机期间将丢失或必须重新输入的可变数据量。示例:如果数据快照间隔和RPO为180分钟,而中断仅持
续2小时,那么考虑到中断期间丢失的数据量,您仍然处于允许恢复和业务流程继续进行的参数范围
内。
● Recovery Time Objective (RTO)
在业务流程中断之后,需要多长时间才能恢复? RTO是业务流程在灾难发生后必须恢复的持续时间和服
务级别,以避免与连续性中断相关的不可接受的后果。RTO指定在中断开始严重且不可接受地阻碍正常
业务操作流之前可以通过的“实时”时间量。
复制是任何企业数据保护解决方案的基本组件,确保关键数据和应用程序可以可靠和有效地复制到不
同的站点或独立的基础设施。虽然企业IT架构师有许多技术选项,但是对于任何成功的企业数据保护
活动来说,都必须具备复制功能。Nutanix在VM、文件和卷组级别提供数据保护功能,因此VM和数据保
持安全。本篇我们来介绍一下Nutanix数据保护功能的各个方面。
保护策略
Nutanix支持多种类型的保护策略,包括一对一或一对多复制。这些策略如下:
● Per-VM Backup。在分支机构或分公司的环境中,为特定VM备份到指定的不同站点的能力特别有用。
通常,只有运行在分支机构位置的VM的子集需要定期备份到中心站点。然而,当复制是基于传统存储
阵列上的时候,这种VM级别粒度的复制是不可能的。在这些传统的环境中,复制是在整个LUN或卷上以
粗粒度级别执行的,因此很难跨多个站点管理复制。
● 选择性双向复制。除了复制选定的VM外,灵活的复制解决方案还必须适应各种企业拓扑。仅仅将VM
从一个活动站点复制到指定的备用站点是不够的。采用双向复制时,一旦发生灾难性故障,可以启用
这个备用站点。支持不同的拓扑要求可以双向复制数据和VM。
● 同步数据存储复制(metro availability)。数据存储可以跨两个站点,以便在发生站点灾难时提供
无缝保护。
Nutanix的Native Replication基础设施和管理支持多种企业拓扑,以满足实际需求。下面是需要考虑
的四个复制选项。
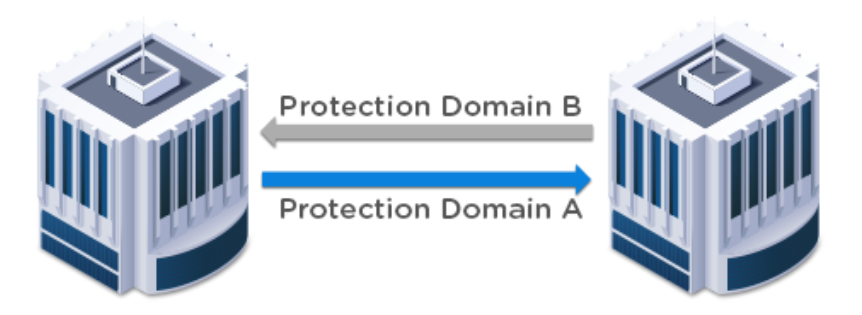
1、Two-Way Mirroring(双向镜像)
对于所有站点都必须支持活动流量的环境,在多个站点之间镜像VM复制的能力是必要的。考虑一个双
站点的例子。站点2作为站点1上运行的选定工作负载的目标。同时,站点1作为站点2上运行的指定工
作负载的数据保护目标。在这个场景中,两个站点上同时运行着活动的工作负载,因此在这两个位置
上都没有空闲资源。与传统的数据保护策略相比,利用这两个位置的存储、计算和网络资源具有显著
的优势,传统的数据保护策略是服务器处于空闲状态,以预测未来的数据灾难事件。
2、One-to-Many(一对多)
在另一种情况下,可能有一个中心站点和多个远程位置。考虑一个示例,其中第一级工作负载运行在
站点1上,站点2和站点3用作远程备份位置。然后可以将Site 1工作负载复制到2和3个位置。在发生数
据灾难事件时,可以在所需的复制站点上启动受保护的工作负载,从而提高VM的整体可用性。
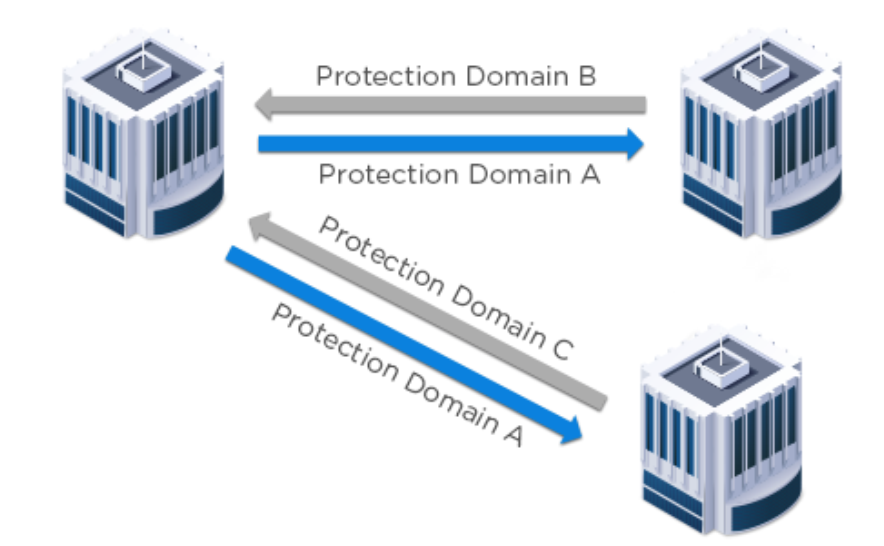
3、Many-to-One(多对一)
在运行于站点1和站点2上的工作负载中,可以将工作负载复制到中心站点3。将复制集中到单个站点可
以提高地理分散环境的操作效率。远程和分支机构(ROBO)是多对一拓扑的经典用例。
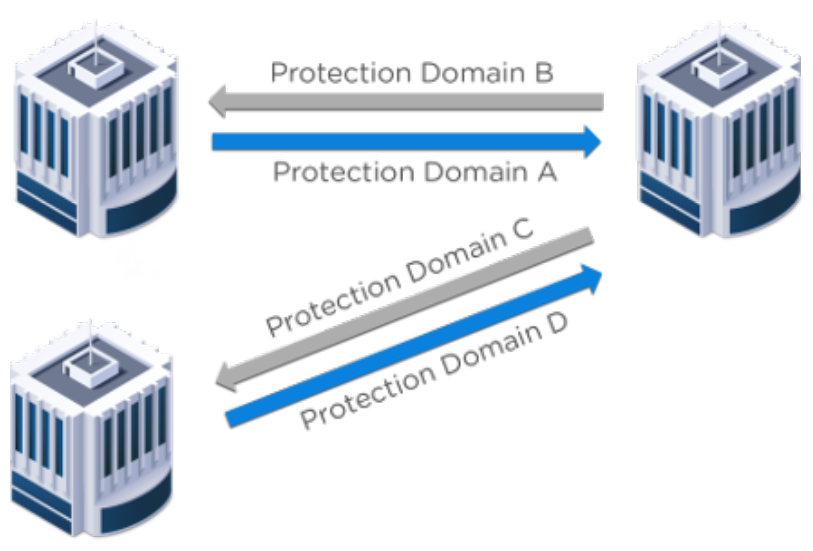
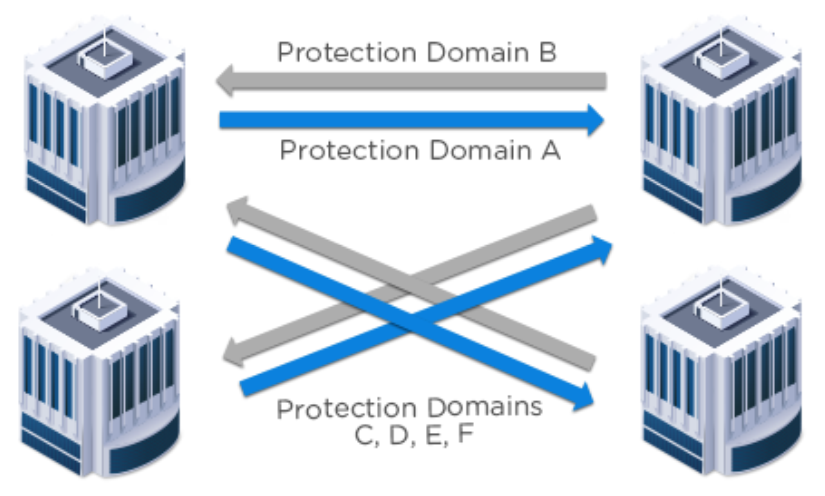
4、Many-to-Many(多对多)
这种拓扑允许最灵活的设置。IT部门拥有最大限度的控制和灵活性,以确保应用程序和服务级别的连
续性。
Nutanix数据保护的概念
Nutanix集群的数据保护特性使用了以下组件和功能:
● Protection Domain(保护域)
保护域分为两种,一种是“Async DR”,另一种是“Metro Availability”。
Async DR:标准(Async DR)保护域是一组定义的实体(VM和卷组),它们在集群上本地备份,并可选
地复制到一个或多个远程站点。这种类型的保护域使用异步数据复制来创建快照。保护域的名称必
须是唯一的。一个实体最多可以位于一个保护域中。集群中的保护域可以处于以下两种模式之一:
● Active: 管理卷组和活动的VM。创建、复制和过期快照
● Inactive: 仅从远程集群接收快照
Metro Availability:城域高可用性,保护域由本地集群中指定的(活动的)存储容器组成,该容器
链接到远程站点上具有相同名称的(备用的)容器,当启用城域高可用性时,在远程站点上发生同步
数据复制。
● Consistency Group(一致性组)
一致性组是保护域中实体的子集。(一致性组是在创建保护域时配置的。)该保护域的一致性组中的
所有实体都以冲突一致的方式执行快照。对于一致性组中的所有VM,快照为组中的所有VM创建一个
快照。
● Snapshot(快照)
快照是VM或卷组在某个时间点的状态和数据的只读副本。
● Time Stream(时间流)
时间流是一组快照,存储在与源VM或卷组相同的集群中。
● Remote Site(远程站点)
远程站点是一个单独的集群,用作复制备份数据的目标位置。可以为集群配置一个或多个远程站点。
● Replication(复制)
复制是将快照从一个集群异步复制到一个或多个远程站点的过程。
● Schedule(计划调度)
计划是一个保护域的属性,它指定快照的拍摄间隔和快照应该保留多长时间。在配置保护域时设置调
度。调度可选地指定要复制到哪个或哪些远程站点。
● Related Entities(关联实体)
关联实体是与要保护的实体关联的VM和卷组。关联可以是直接的(直接通过hypervisor挂载或者通过
iSCSI的形式),也可以是传递的(如果一个卷组附加到两个VM,则认为这些VM彼此相关)。例如,如果
名为VG1的卷组作为SCSI磁盘直接连接到名为VM1的VM,则VG1和VM1是相关实体。如果VG1也连接到一
个名为VM2的VM,则VG1和VM2是相关实体。在这个配置中,VM1和VM2也被认为是相关的实体,因为它
们与相同的卷组相关联。
Cloud Connect
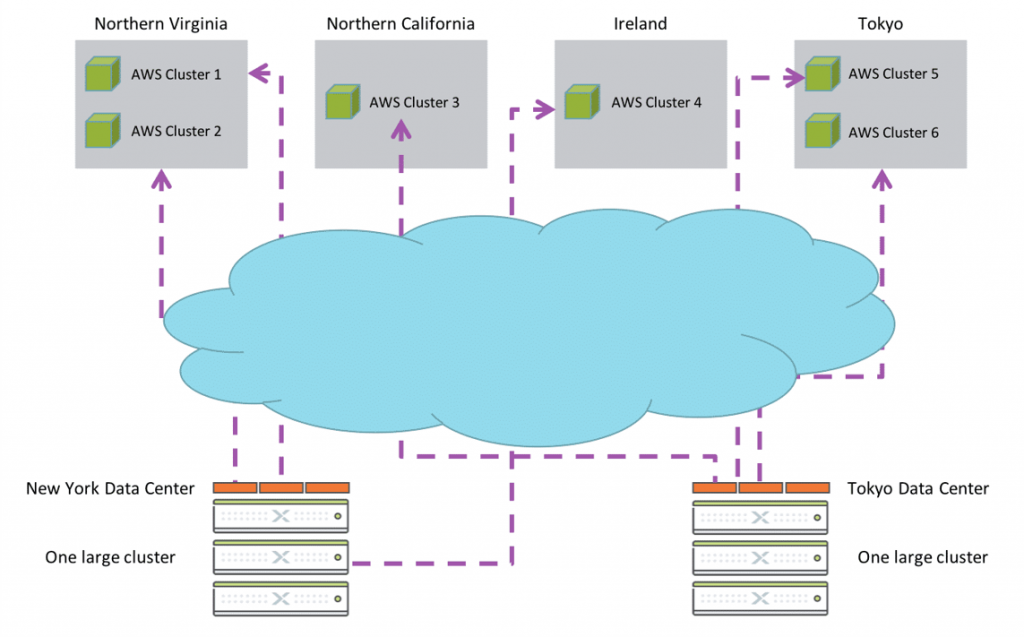
1、Nutanix Cloud Connect特性允许将Amazon Web Services (AWS)配置为虚拟机备份的远程站点。
AWS远程站点是一个单节点集群,它创建一个m1.xlarge的EC2实例。在AWS S3中创建了一个bucket,
它拥有一个30TB的存储。通过Nutanix Cloud Connect特性还可以配置Azure虚拟机(目前是D3)。通
过Cloud Connect能够将虚拟机和文件的副本备份到本地群集和位于AWS或Microsoft Azure云上的
Nutanix控制器虚拟机(CVM),并可以从中恢复这些副本。云上的Nutanix控制器虚拟机(CVM)是
一个单节点集群,有一个30TB的磁盘连接到该节点,可用磁盘容量为20TB。
2、Amazon或Azure客户只对使用的容量收费(不针对完全容量收费)。一旦通过Web控制台进行配置,
远程站点集群将像您创建和配置的任何其他远程站点一样,通过数据保护仪表板进行管理和监控。要
登录到云上的Nutanix控制器VM,请从远程站点群集的数据保护仪表板获取IP地址,并从源群集控制
器VM获取ssh到IP地址。
3、Amazon S3用于存储数据(区段),Amazon Elastic Block store (EBS)用于存储元数据。然后用
户使用Amazon管理工具来管理和监视计费和相关使用。当AWS远程特性将快照数据复制到AWS时,AWS
上的Nutanix控制器VM在S3存储上创建一个bucket。bucket名称为:
ntnx-cluster_id-cluster_incarnation_id-disk_id。
4、Cloud Connect的限制及建议
● 目前不支持Microsoft Azure资源管理器(ARM)基础设施。
● 对于配置为复制到云远程站点的每个保护域,建议只有一个虚拟机。
● 不建议配置具有云连接功能的vStore保护域和备份复制。
● 不要使用运行在云上的Controller VM的Nutanix Web控制台,因为它不受支持。
● 不要在云实例上启用重复数据删除。
● 不建议在源集群上启用重复数据删除功能。
● 不要使用云实例上的DoNotUse-sp存储池来创建容器。
● 如果不删除云远程站点,则无法删除用于创建云远程站点的凭据。
● 如果您的网络位于代理服务器之后,则不能使用云连接功能。
● 更改vStore映射会导致相关的保护域将受保护实体完全复制到新指定的目标容器,就像初始复制
一样。因此,映射更改会导致对远程站点存储资源的过度消耗。请联系Nutanix支持,以帮助清理先
前指定容器中的快照。
Nutanix Guest Tools (NGT)
1、Nutanix Guest Tools(NGT)是一个安装在GuestVM中的软件包,用来启用Nutanix提供的一些高级
功能。NGT包由以下组件组成:
● Nutanix Guest Agent (NGA) service
负责与Nutanix CVM通信。
● File Level Restore CLI
从VM快照中执行自助服务文件级别的恢复(self-service file-level)。
● Nutanix VM mobility drivers
提供在ESXi和AHV之间迁移VM的驱动程序、Hypervisor就地转换和跨Hypervisor灾难恢复(CH-DR)
● VSS requestor and hardware provider for Windows VMs
对AHV或ESXi上的Windows VM启用与应用程序一致快照
2、在Windows VM上安装NGT并配置应用一至性快照,要启用此功能,先确保在Windows VM上已经启
用了Shadow Volume Copy功能。
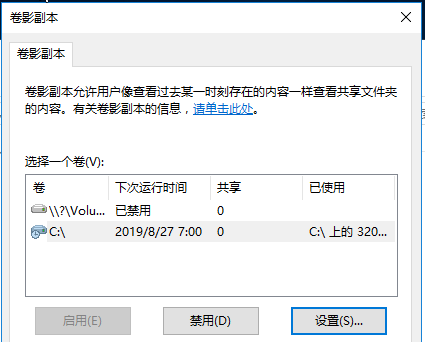
3、选择要安装NGT的虚拟机,然后点击“Manage Guest Tools”按钮。如下图,选择启用并挂载NGT,
并选择启用”SSR”和”VSS”。
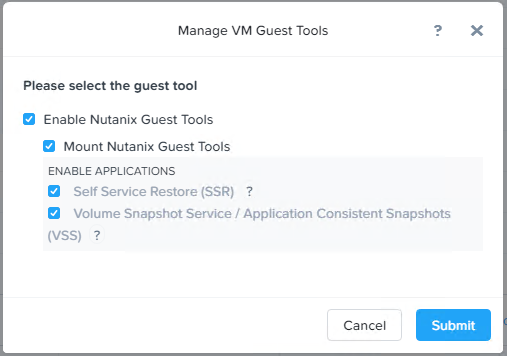
4、在Windows VM中执行挂载上来的光盘中的安装程序,完成安装后重启系统。
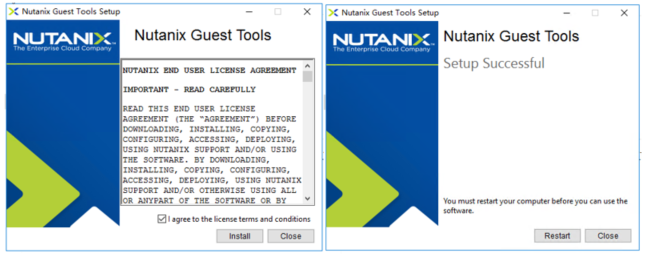
5、VM重启完双后,可以在程序中看到NGT和VM Mobility已经安装完成,同时,在桌面上可以看到SSR
的快捷方式。

应用一致性快照
1、Nutanix 提供原生的 VmQueisced Snapshot Service(VSS) 功能静默操作系统和应用操作,
以确保完成应用一致性快照。该方案用于Windows和Linux 客户虚拟机。
2、创建应用一致性快照的前提条件如下:
● Nutanix 平台
必须配置集群Virtual IP(VIP)
● 客户操作系统/用户虚拟机
必须安装NGT
必须能够连接集群VIP的2074端口
● 容灾配置
客户虚拟机所在的PD必须启用”Use application consistent snapshots”
3、在Prism Web Console上进入数据保护页面,点击右上角的”+保护域”,选择“Async DR”。
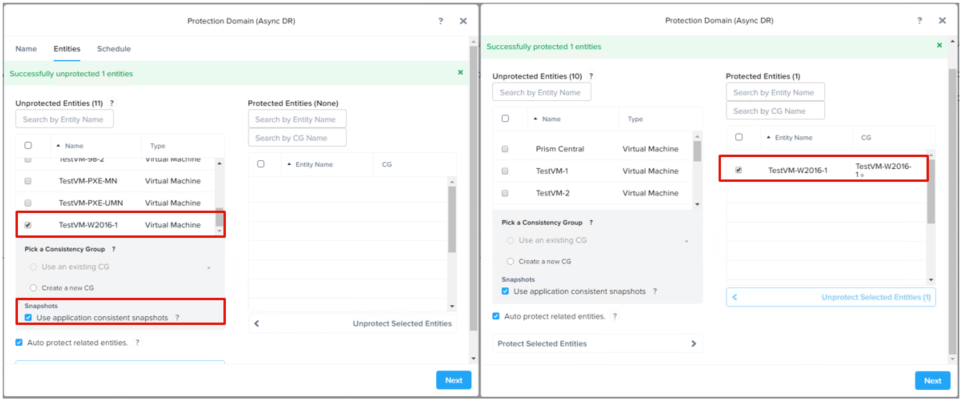
4、选择要进行保护的虚拟机,并勾选“Use appliction consistent snapshots”。然后将选中的
虚拟机添加到右侧的列表当中。
5、设置备份计划,主要是备份频率和存放地点,这里我们先选择存放在本地,也就是Cluster本地。
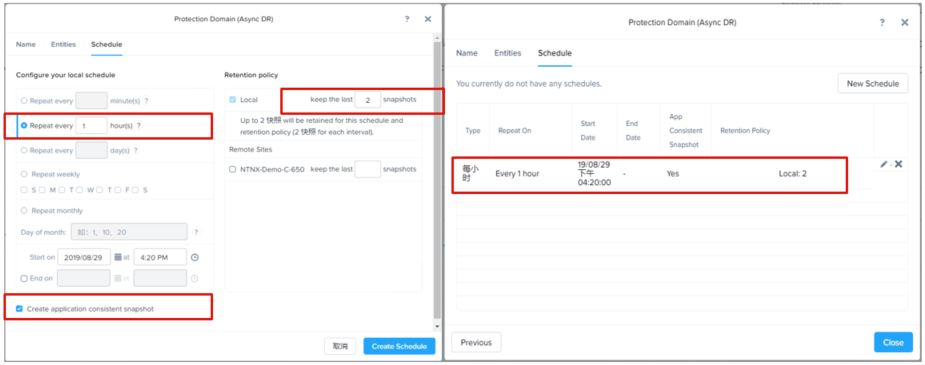
6、创建完成后,在”Async DR”页面可以看到新创建的保护域,并且快照模式为应用一致性快照。
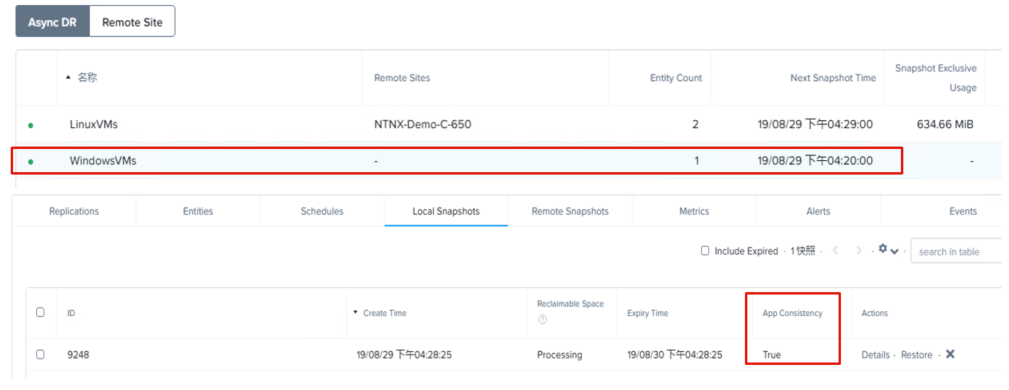
7、如下图已经按计划进行了三次应用一致性快照。

8、对于Linux虚拟机,其VSS方案类似于Windows方案, 但是其是借助于脚本而不是Microsoft VSS
框架实现的。对Linux执行VSS同样也需要先安装NGT,将NGT挂载到虚拟机,然后执行以下命令进行安
装即可。
sudo mount /dev/sr0 /mnt
sudo /mnt/installer/linux/install_ngt.py
复制和容灾(DR)
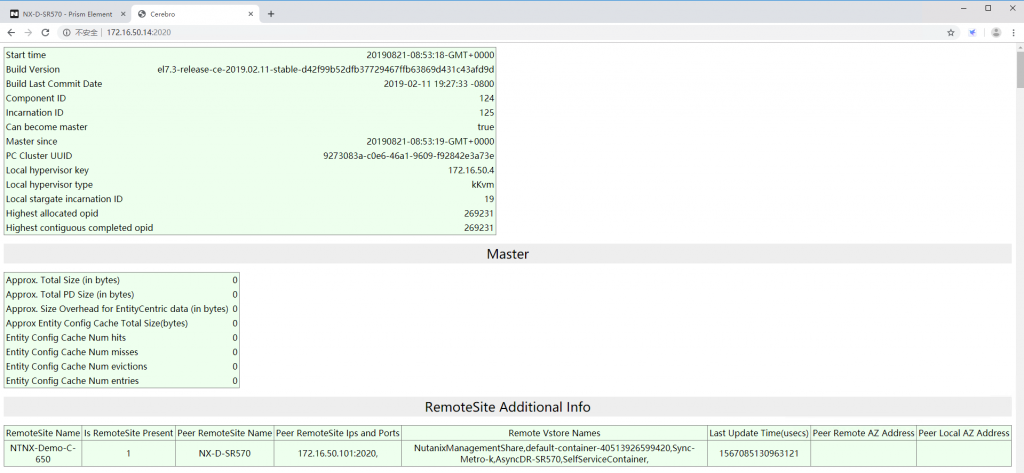
1、Nutanix 提供原生的容灾(DR)和复制功能,它们构建于”快照”和”克隆”等功能之上。Cerebro
是在分布式存储(DSF)中负责管理容灾和复制的组件。Cerebro 运行于每个节点之中,通过内部选
举产生Master(类似于 NFS Master),并由此节点管理复制任务。如果当Cerebro Master所在的CVM
发生故障,剩余的节点将选举出新的 Master。通过:2020,即可打开Cerebro 的相关界面。
2、容灾功能可以分解为以下关键要点:
● 复制拓扑
前面我们已经介绍过几种主要的复制网络拓扑:点对点(Site to site),菊花链(一对多,多对
一),全网状/部分网状(多对多) 。相对于传统的方案,它们仅提供”点到点”或”菊花链”的方式,
Nutanix提供”全网状”或更加灵活的”多到多”的拓扑方式。这将让管理员能够灵活的配置复制功能,
从而更好的满足需求。
● 复制周期
Nutanix通过Cerebro实现数据的复制。Cerebro服务分为Cerebro Master和Cerebro Slave。
Cerebro Master由动态选举产生,除Cerebro Master节点之外的CVM中,均运行Cerebro从属服务
(Cerebro Slaves)。一旦”Cerebro Master”所对应的CVM宕机,新的Master将被自动选举产生。
Cerebro Master 负责委派任务给本地的Cerebro从属节点,以及协调远端的Cerebro Master,实
现容灾数据复制。在复制过程中,Cerebro Master将负责确认哪些数据需要被复制,同时将任务委
派给Cerebro从属节点,随后将告知Stargate哪些数据需要被复制,需要被复制到哪里。在复制过
程中,复制数据在多个层面被保护。源端Extent读使用校验码保证源数据的一致性,类似于DFS读,
在目标端,新的Extent(s)也会生成校验码(类似于DFS写)。 TCP提供网络层面的一致性。
● 全局去重
分布式存储DSF可以仅通过更新元数据(Metadata)指针实现重复数据删除。同样的实现方式也可被
用于容灾和复制中。通过网络发送数据之前, DFS将检查远程站点中是否已经存在相关数据的记录
(fingerprint)。如果有,则不发送数据,仅更新元数据。如果远程站点中没有此数据记录,数据将
被压缩并发送至目标站点中。此时,该数据将被用于两个站点中的重复数据删除。
Async与NearSync
1、Async属于传统异步复制功能,对于RPO大于或等于60分钟的调度仅被称为异步调度,并使用完整
快照。计划可以按照小时、天、周和月进行配置。
2、NearSync近同步复制,对于RPO在1到15分钟之间的调度称为近同步调度。实际上,这些调度也是
异步调度,但是它们有15分钟或更低的RPO。调度计划可以用分钟为单位来配置。注意,不允许设置
15到59分钟的调度计划。
3、NearSync提供了两全其美的功能:除了非常低的RPO(与同步复制相近)之外,对主I/O延迟
(与异步复制相同)的影响为零。这意味着允许用户具有非常低的 RPO,而又不会产生对写入的
同步复制的开销。此功能使用称为轻量级快照(LWS)的新快照技术。与使用异步方式的传统基于
虚拟磁盘的快照不同,它利用标记并且完全基于 OpLog 来完成(与在Extent Store 中完成的虚
拟磁盘快照相比)。
4、如下图,在数据保护的页面中,可以看到Async DR标签。当用户配置快照频率<= 15分钟时,将自
动利用NearSync技术进行保护。在此之后,初始种子快照被执行然后被复制到远程站点。一旦这个过
程在60分钟内完成(可以是第一个或第N个),除了开始LWS快照复制之外,另一个种子快照将被立即
执行和复制。一旦第二个种子快照完成复制,所有已复制的LWS快照将变为有效,并且系统处于稳定的
NearSync运行状态中。如果用户配置快照频率大于等于1小时,则使用异步复制。
5、使用NearSync的要求与限制
● 只支持1:1复制
● 主站点和远程站点上的集群至少需要3个或更多节点
● 支持从1分钟到15分钟的日程配置。无法配置调度从16分钟到59分钟
● 集群中每个SSD的容量必须至少为1.2 TB
● 为了获得最佳性能,混合存储配置中最小SSD大小需求等于2 * 1.9 TB
● 全闪集群没有任何特定的SSD大小要求
● 每个保护域中最多有10个实体(VM或卷组),建议将形成单个应用程序的虚拟机分组特定应用程
序故障转移粒度的保护域
● 如果节点超过40TB,则不要在集群上启用近乎同步
● 支持ESXi和AHV,不支持Hyter-V
● 支持除IBM Power Systems之外的所有平台
● 不支持链接克隆虚拟机
● 不支持Metro containers
● 不支持Self-Service Restore
● 不支持Nutanix Files (Files)
Remote Site(远程站点)
1、远程站点是一个用来存储复制被保护域的数据的目标位置。远程站点可以是一个物理的集群,
也可以位于公有云之上,例如ASW和Azure。
2、要使用网络映射,需要在源集群和目标集群上创建相同的网络连接和VLAN。注意不要创建指
向单个目标集群的多个远程站点,否则,将生成警告。
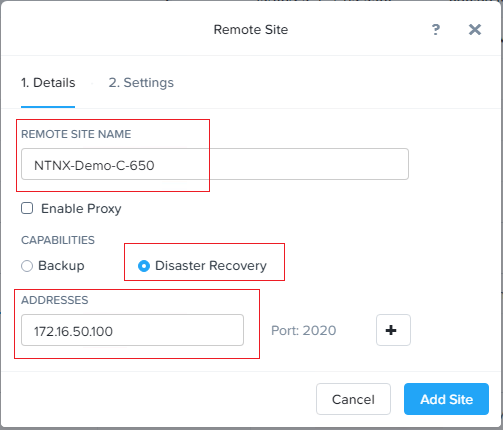
3、在数据保护页面的右上角点击”+远程站点”,选择”Physical Cluster”,填写远程站点的集群
名称,在Capabilities这里包括两个选项:
● Backup
只用作备份站点,允许将远程站点用作备份(复制)目标。这意味着可以将数据备份到该站点,并
且可以从该站点检索快照来本地恢复,但是没有启用故障转移保护(即直接从远程站点运行故障
转移VM)。
● Disaster Recovery
灾难恢复允许将远程站点用作备份目标和动态恢复源。这意味着故障转移VM可以直接从远程站点
运行。
4、地址这里填写远程站点集群的虚拟IP地址。
5、配置源集群与目标集群的网络映射,确保网络一致。配置vStore映射,Source vStore是指被保
护的虚拟机所在的存储容器,Destination vStore是指远程站点的集群中用来做复制的存储容器。
每个vStores条目的映射都代表本地源存储容器和远程目标存储容器之间的关联。
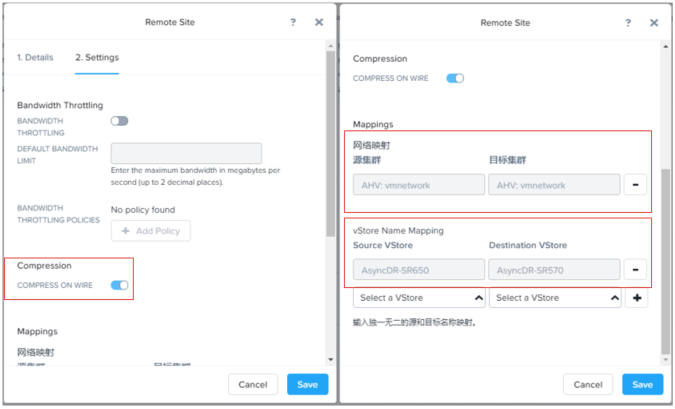
6、注意:还必须将本地集群配置为远程集群上的远程站点,以便将远程站点用作存储数据复制的目
标位置。如果当前不是这种情况,则登录到远程集群并将本地集群配置为该集群的远程站点。
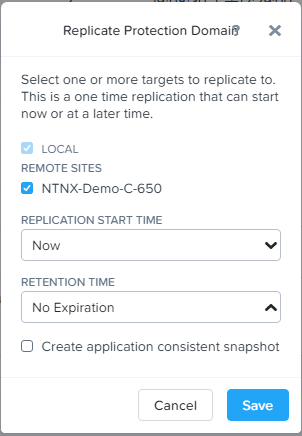
7、远程站点创建完成后,我们创建一个保护域,并设置将VM快照复制到远程站点。

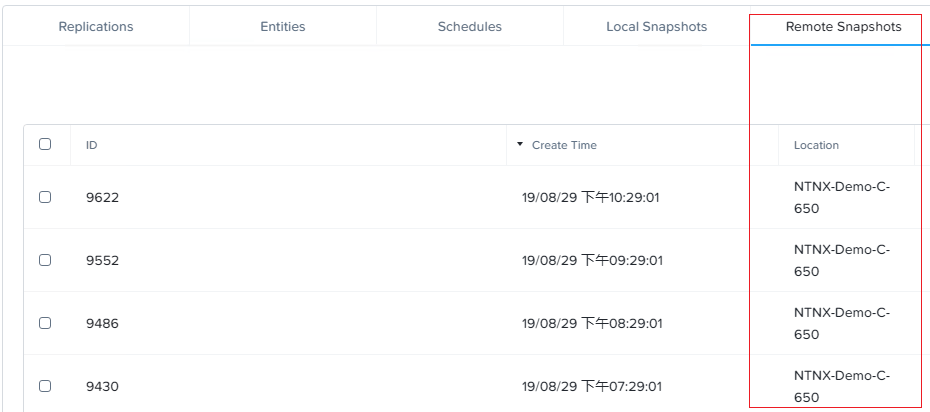
8、经过几次按计划的复制之后,可以看到该保护域已经在远程站点存储数份快照。
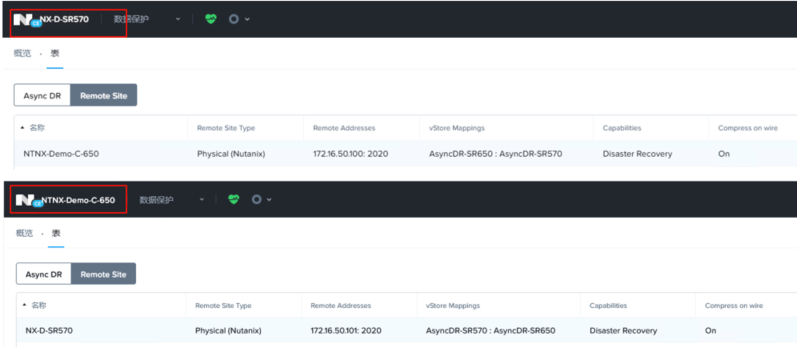
9、分别在两个站点上查看“远程站点”
Synchronous Replication(同步复制)
同步复制是在Metro Availability配置中在两个站点之间同步复制数据的特性。在任何一个站点发
生灾难时,都可以在另一个站点上获得实时数据。保护域可根据以下情况配置为”城域高可用”或者”
同步复制”。
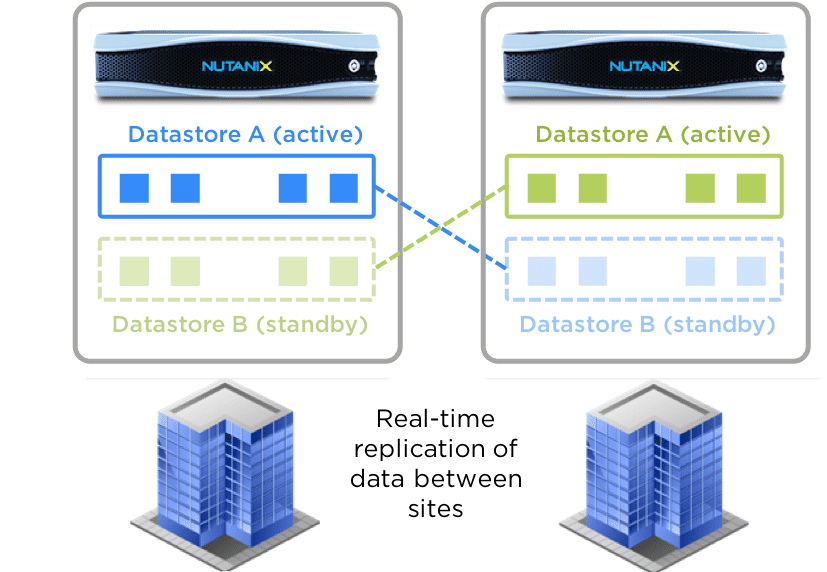
● Metro Availability(城域高可用性)
Nutanix具有Stretch Clustering(延伸集群)的能力,允许它的计算和存储集群可以跨越多个物
理站点。这种部署架构下,计算集群可以跨越两个站点并共享一个存储池。因此,两个集群上的容
器(数据存储)名称必须相同。这将VM HA集群从一个站点扩展到两个站点之间,提供近乎等于0的RTO。
这种部署架构下,每个站点都有自己的Nutanix 集群,但其中容器(Container)的写操作被同步复
制到远端的站点之中。当站点发生故障, HA将发生切换, 虚拟机将在另一个站点启动。如果站点间
的网络链路故障,集群将分别独立运行。一旦网络链路修复,站点将进行增量同步,并重新恢复数据
同步。Hypervisor需要是ESXi,并且需要满足跨站点的单个vSphere集群配置的要求。
● Synchronous replication
Hypervisor可以是是ESXi(未配置Metro Availability),也可以是Hyper-V。
手动快照
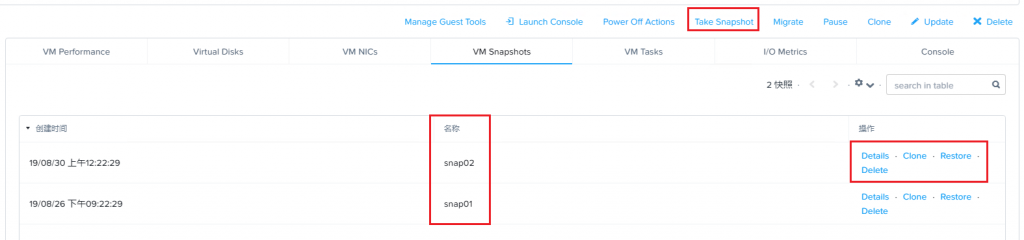
1、可以为虚拟机手动执行创建快照的操作,选择虚拟机,然后点击”Take Snapshot”。这种方式创建
的快照只能存储在集群本地。
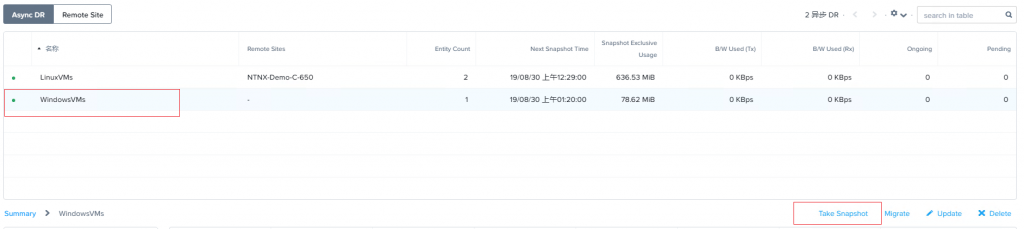
2、同样可以对保护域执行手动快照,快照会对保护域中的所有VM执行快照操作,并且可以选择快照是
保存在集群本地,还是保存到远程站点,还可以设置过期时间。以及是否执行应用一致性快照。
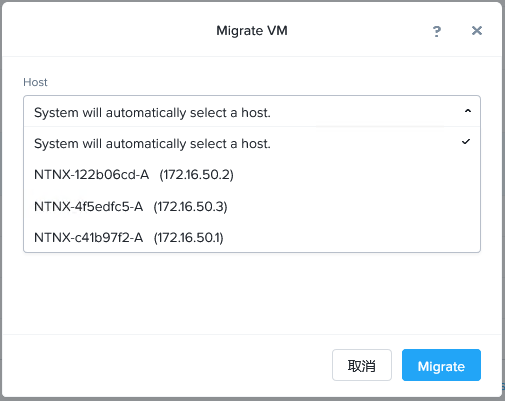
迁移虚拟机
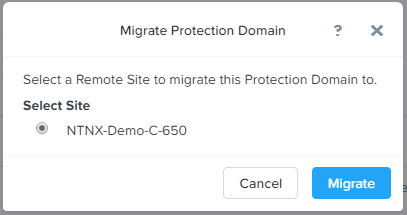
1、对于保护域中的虚拟机,可以选择迁移到远程站点。


2、在Prism中查看迁移成功后的状态。
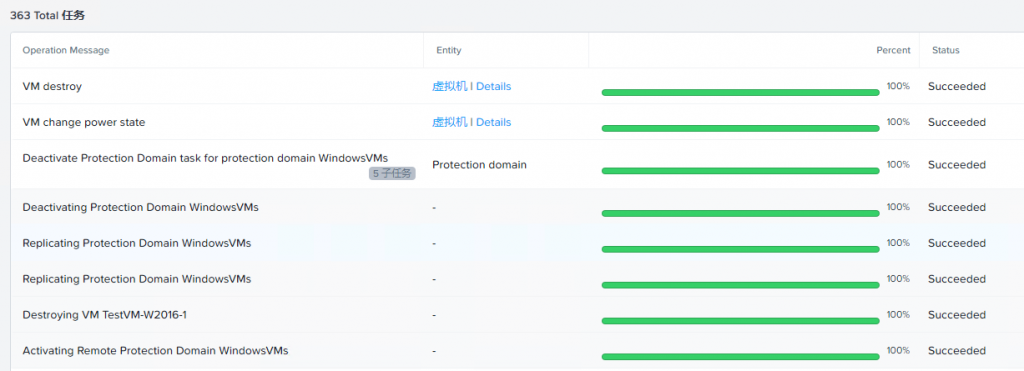
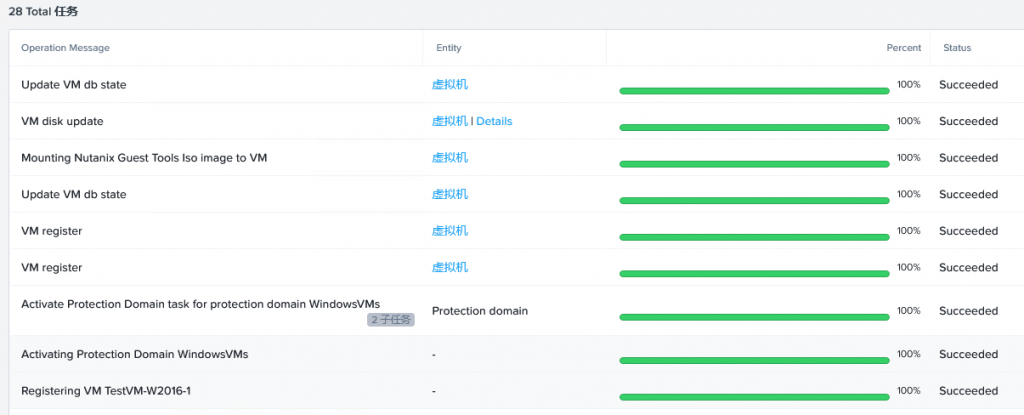
3、虚拟机迁移到新站点后,不会自动开机,可以检查一下虚拟机的配置是否正确然后再开机。
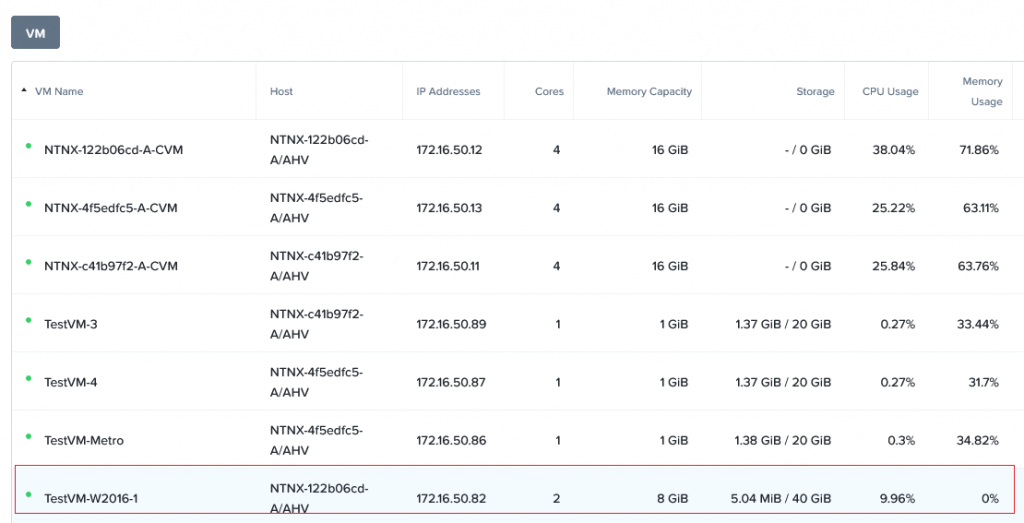
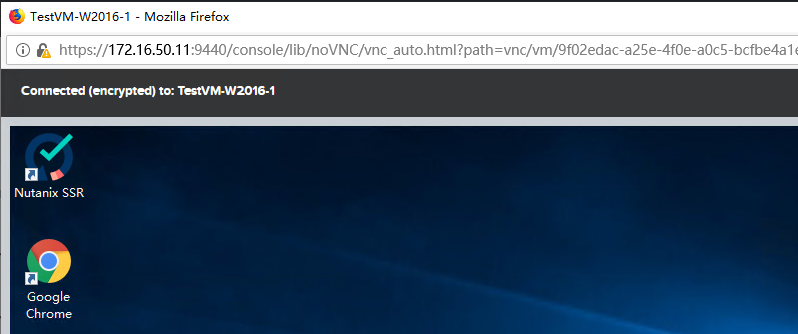
4、确认虚拟机迁移后可以正常启动及运行。
5、虚拟机迁移后,之前执行的快照并不会跟随虚拟机一同迁移,比如原来在保护域中的本地快照,
迁移后就会变成远程站点快照。迁移到远程站点之后,其上面存储的快照就会变成本地快照。
6、也可以将虚拟机迁移到本地集群中的不同主机。